Gestern, am Sonntag, bin ich mal wieder von Essen nach Nijmegen gefahren. Das Ganze ist eine ziemliche Tortur geworden. Einen blutigen Zwischenfall gab es schon vorher beim Ticketkauf über die Bahn-Website, doch dazu später mehr. Kommen wir erst einmal zur Reise selbst.
Die Reise
Essen Hauptbahnhof
Die Bahnreise startete in Essen am Hauptbahnhof. Meine erste Zwischenstation war Oberhausen Hauptbahnhof. Das ist praktisch direkt nebenan, nur 12 Minuten Fahrt. Zum Umsteigen hatte ich zehn Minuten Zeit, also eigentlich genau richtig: Genug, um beim Umsteigen nicht in Stress zu geraten, nicht so viel, dass man ewig warten muss.
Nur dass in Essen am Hauptbahnhof direkt angezeigt wurde, dass der Zug nach Oberhausen neun Minuten Verspätung hat. Kurze Zeit später kam dann eine Durchsage, dass die Verspätung zehn Minuten ist. Dann noch eine. Runter auf fünf Minuten Verspätung. Dann sechs Minuten. Am Ende ist der Zug 7 Minuten zu spät in Essen angekommen, schaffte es aber, diese Verspätung bis Oberhausen auf 12 Minuten auszubauen.
Oberhausen Hauptbahnhof
Nun ist es so, dass ich normalerweise von Oberhausen direkt nach Arnhem fahren kann. Wenn nicht gerade Schienenersatzverkehr (SEV) ist. So wie Anfang 2022, wo sich meine Fahrtzeit von etwa 2,5 Stunden mehr als verdoppelt hat, weil die Bahn-Website mir nicht mitgeteilt hat, dass es auf der Strecke SEV gibt und ich lieber eine andere Route nehmen sollte.
Zumindest in dieser Hinsicht hat sich die Bahn gebessert. Momentan ist zwischen Düsseldorf und Oberhausen Sterkrade SEV, und die Bahnwebsite hat das bei der Routenplanung auch eingeplant. Ich musste den Bus 3 von Oberhausen Hauptbahnhof nach Oberhausen Sterkrade nehmen. Dass das SEV ist, hat mit die Website aber nicht mitgeteilt.
Nun war ich ohnehin schon zu spät, habe mich aber trotzdem beeilt. In der Hoffnung, ich könnte den Bus vielleicht doch noch erwischen. Nur… Am Hauptbahnhof fuhr kein Bus 3. Alle Buslinien sind entweder mindestens dreistellig oder haben die Präfixe SB (Schnellbus) oder NE (Nachtexpress).
Ich gibt es in Oberhausen am Hauptbahnhof einen ganzen Haufen nummerierter Bussteige. Auf meinem Ticket, auf dem alle Bahnsteige verzeichnet sind, ist der Bussteig von Bus 3 nicht verzeichnet. Obwohl die Bahn diese Information hat, denn der Herr bei der Bahnauskunft konnte sie mir ohne Probleme sagen.
Die SEV-Busse sind also an Bussteig 10, und sind nicht als „Bus 3“ markiert, sondern als SEV. Zumindest auf den Anzeigetafeln. Erinnerung: Ich wusste, bis ich nachgefragt habe, nicht einmal, dass „Bus 3“ einen Schienenersatzverkehrbus ist.
Immerhin, dank der Auskunft wusste ich Bescheid. Nur fuhr der nächste SEV erst eine Stunde später (ist halt Schienenersatzverkehr, fährt im selben Takt wie die Züge). Die Busse, die sonst noch angeblich vom Hauptbahnhof nach Sterkrade fuhren, waren nirgendwo zu sehen. Außerdem konnte ich ums Verrecken nicht herausfinden, ob ich die mit meinem Bahnticket hätte benutzen dürfen.
Und eine Stunde später, ließ sich auch mein SEV-Bus nicht blicken. In Sterkrade hatte ich nur sechs Minuten Zeit zum Umsteigen.Bei Fünf Minuten Verspätung wurde der Bus dann von der Anzeige gestrichen, so dass ich ein bisschen in Panik geriet, dass ich noch eine Stunde hier herumstehen müsste.
Zu allem Elend hat auch noch jede dritte Person auf den Bussteigen geraucht. Es war voll, und sie haben sich gleichmäßig verteilt, so dass man ihnen nicht ausweichen konnte.
Irgendwann kam der Bus dann doch.
Oberhausen Sterkrade
Der Bus in Oberhausen Sterkrade hatte Verspätung, aber glücklicherweise trat das auch auf den Zug zu. Er hatte zehn Minuten Verspätung laut Durchsage, aber 12 Minuten nach fahrplanmäßiger Abfahrt war er noch nicht da. Dann kamen drei Durchsagen, direkt hintereinander, dass dieser Zug 20 Minuten Verspätung habe. Kurze Zeit später noch eine Durchsage, 25 Minuten.
Als der Zug dann endlich kam, gab es keine Sitzplätze mehr. Erst nach einer knappen Dreiviertelstunde Fahrt wurde ein Sitzplatz frei.
Arnhem und der Rest
Für Arnhem musste ich mir dann auch noch eine andere Verbindung suchen, weil ich ja deutlich zu spät war. Am Ende bin ich dann 1,5 Stunden zu spät angekommen, bei einer geplanten Fahrtzeit von 2,5 Stunden.
Autofahren ist auch Scheiße
Kommen wir nun zum Titel dieses Blogposts. Im ersten Zug, zwischen Essen und Oberhausen Hauptbahnhof wurden Informationen zu Baustellen im Zug angezeigt. Mit dem Hinweis (in etwa, Wortlaut kenne ich nicht mehr): „Bevor sie auf das Auto umsteigen, bedenken Sie: Auch dort haben sie Baustellen und Staus“.
Stimmt. Aber vielleicht sollte man den Marketing-Spezis bei der Bahn mal erklären, dass „die Alternativen sind auch Scheiße“ nicht gutes Marketing ist.
Der Ticketkauf
Der Ticketkauf war ein traumatisches Erlebnis für mich. Die Bahn hat ein neues Frontend für den Kartenkauf und es ist noch schlimmer als vorher.
Update: Ok, jetzt, eine Woche später als geplant, kommt endlich der Rant über die Fahrplanauskunft. Grund für die Verzögerung war ein kleines Souvenir von der Bahnreise: Eine Covid-19-Infektion (Empfehlung: Tragt FFP2-Masken in Zügen).
Zurück zum Thema: Die Online-Fahrplanauskunft/Ticketshop. Ich habe also mühsam Start-und Zielbahnhof sowie eine Zeit angegeben (und es ist wirklich mühsamer als auf anderen Seiten, weil die Bahn-Website sich alle Mühe gibt, meinen Inputfokus woandershin zu lenken), sehe die Liste der möglichen Verbindungen und denke: „Verdammt, ich wollte noch meine Bahncard angeben“.
Früher war das einfach. Ich konnte ganz am Anfang ein Dropdown öffnen. Das waren zwei Schritte:
- Dropdown anklicken
- richtige Bahncard auswählen
So schnell ging das. Heute ist das komplizierter. Ich habe eine illustierte Anleitung gemacht.
Schritt 1: Anfrage ändern
Der erste Schritt ist noch harmlos. Man muss die Stelle ausfindig machen, wo man die Bahncard hinzufügen kann. Oben auf der Seite findet sich unter anderem das hier:

Prima, dann ändern wir doch mal die Anfrage.
Schritt 2: ähh… Anfrage ändern?
Durch einen Klick auf „Anfrage ändern“ öffnet sich dieses Modal:
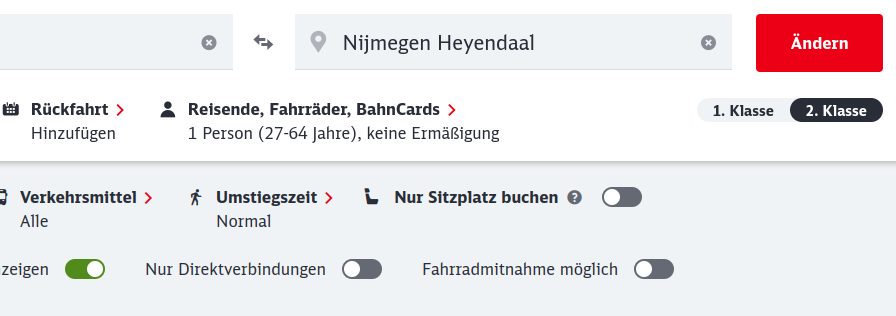
Ok… oben links in der Ecke ist ein „Ändern“-Button. Aber vielleicht hilft es ja, wenn ich einfach auf „Reisende, Fahrräder, Bahncard“ klicke.
Schritt 3: Reisende, ähh… Bahncard hinzufügen
Dieser Klick öffnet ein weiteres Modal:
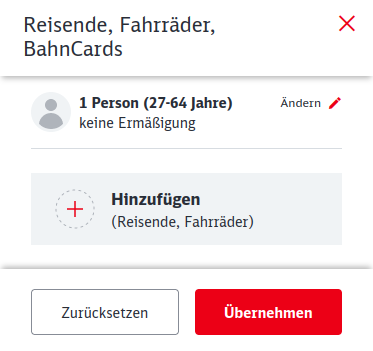
Nun sind ja alle Informationen da, aber der typische Benutzer liest ja nicht alles, sondern klickt sich schnell durch. Ich will eine Bahncard hinzufügen, oder? Also klicke ich auf „Hinzufügen“.
Schritt 4: Eine Bahncard hinzufügen
Es öffnet sich natürlich noch ein Modal:
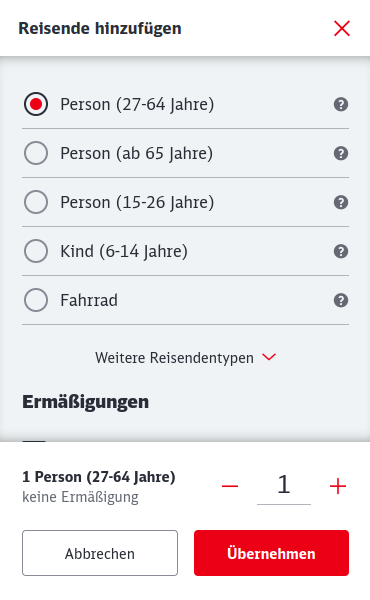
Äh… wo sind denn jetzt die Bahncards? Warte, da steht „Ermäßigungen“! Scrollen wir doch mal in dem Modal nach unten!
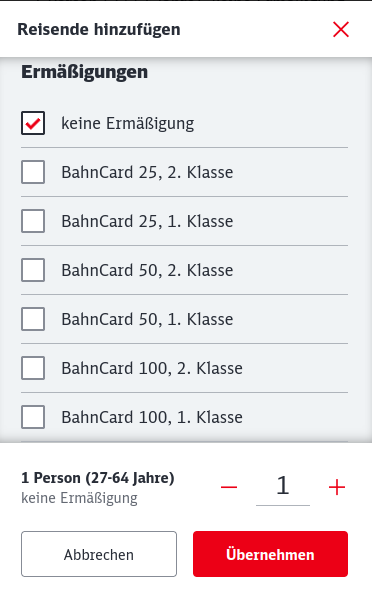
Ah, prima, da sind ja die Bahncards!
Schritt 5: Eingaben korrigieren
So, einmal auf „Übernehmen“ geklickt und schon… Moment mal, was soll das?
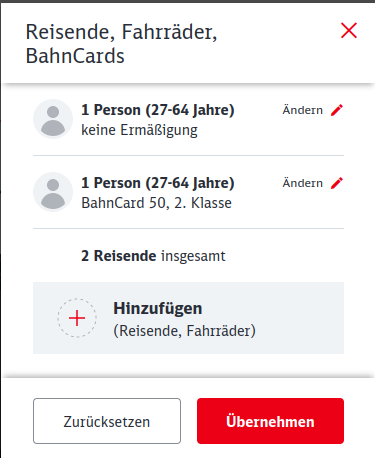
Mist. Ich wollte keine zwei Reisenden. Ich wollte doch nur eine Bahncard hinzufügen? Wie kann man die jetzt wieder löschen? Ah, prima, wenn man auf „Ändern“ klickt, kommt ein Modal sehr ähnlich zu dem aus Schritt 4. Nur dass man hier halt den bestehenden Eintrag ändert.
„Löschen“ gehört auch dazu. Warum man zum Löschen ein Modal öffnen soll, anstatt es einach mit einem Button in der Liste zu machen, ist mir schleierhaft. Aber wenigstens kann ich hier auch Bahncards nach Lust und Laune hinzufügen. Ich muss es nur mit „Übernehmen“ bestätigen.
Damit lande ich wieder in dem Modal aus Schritt 3, nur dieses Mal mit den korrekten Angaben.
Schritt 6: Noch einmal „Übernehmen“ klicken
Um dieses Modal zu schließen, muss ich dann noch einmal auf „Übernehmen“ klicken. Ein bisschen zu viel des Guten, aber ok. Damit Bin ich wieder im ersten Modal:
Prima. Jetzt nur noch dieses Modal schließen. Das geht entweder mit einem Klick auf das X oben in der Ecke (das es nicht auf den Screenshot geschafft hat) oder, indem man einfach neben das Modal klickt.
Aber… Huch!
Die Bahncard ist noch nicht ausgewählt! Was zum…?
Schritt 7: Zurück zu Schritt 1
Ich habe das Ganze mehrmals durchprobiert. Obwohl die Bahncard jedes Mal zwei Mal übernommen habe, wurde sie nie übernommen.
An diesem Punkt war ich wirklich verzweifelt. Eine halbe Stunde und einen blutigen Kampf mit der Website später hatte ich endlich die Lösung: Ich muss in dem ersten Modal noch einmal auf „Ändern“ klicken.
Wider Erwarten öffnet sich dann nämlich nicht noch ein Modal. Stattdessen wird das Modal geschlossen und die Änderungen übernommen.
Zusammenfassung
Um eine Bahncard hinzuzufügen, musste man früher ein Dropdown benutzen.
Jetzt muss man nicht ein, nicht zwei, sondern drei Modale in Reihe öffnen und die Eingaben nicht ein, nicht zwei, sondern drei Mal bestätigen. Und um allem die Krone aufzusetzen, sind die buttons nicht konsistent benannt. In der Regel öffnet ein „Ändern“-Button ein Modal und ein „Übernehmen“-Button bestätigt die Eingaben. In einem Fall öffnet der „Ändern“-Button kein Modal sondern übernimmt die Funktion des „Übernehmen“-Buttons.
Und dann ist es viel zu leicht möglich, aus Versehen alle Eingaben zu verwerfen, selbst die, die man bereits zwei Mal übernommen hat.
In Punkto User Interface und User Experience bestenfalls eine 5 (mangelhaft). Ich kenne das ja aus eigener Erfahrung, dass man sein UI gerne aus dem Bauch heraus entwirft, aber das ist kein guter Ansatz für eine Website, die jeden Tag von unzägligen Reisenden benutzt wird.
Das Teil braucht dringend eine Überarbeitung.